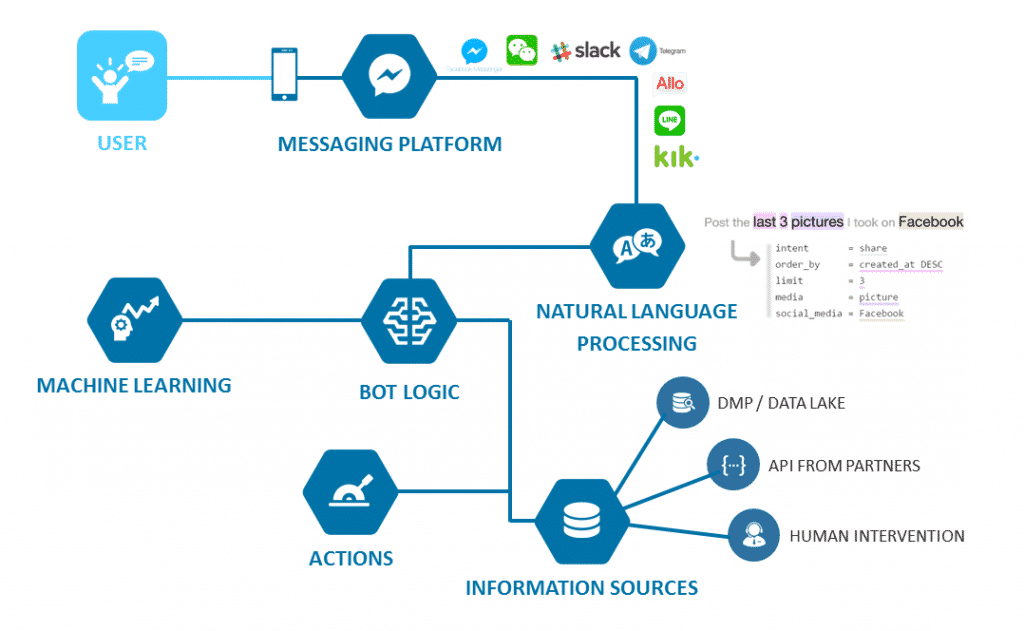
チャットボットを作成するときの目標は、人間の干渉を最小限に減少するか、まったく必要としないものにすることです。これは2つの方法で実現できます。
一番目の方法では、カスタマーサービスチームがAIから提案を受け、カスタマーサービスの方法を改善します。二番目の方法には、すべての会話自体を処理し、カスタマーサービスチームの必要性をなくす、深層学習チャットボットが含まれます。
チャットボットの力のおかげで、フェイスブックのメッセンジャーのチャットボットの数が1年以内で10万から30万に増加した。 MasterCardなどの多くの 人気ブランドも、独自のチャットボットをすぐに作成します。チャットボットとCMS を接続する ウェブサイトも一般的な方法となっており、関連するコンテンツの豊富なソースを提供しています。
しかし、ブランドがそのようなチャットボットをどのように活用できるかを説明する前に、ディープラーニングチャットボットが何かを見てみましょう。
ディープラーニングチャットボットとは何ですか?
ディープラーニングチャットボットは、「ディープラーニング」と呼ばれるプロセスを通じてゼ最初から直接学習します。このプロセスでは、チャットボットは機械学習アルゴリズムを使用して作成されます。ディープラーニングチャットボットは、すべてのデータと人間間の対話からを学習します。
 ルアン・トング・ティン
ルアン・トング・ティン
チャットボットは、テキスト上で意識を発達させるように訓練されており、人々と会話する方法を教えることができます。または、映画の会話やスクリプトを使ってチャットボットを教えることもできます。ただし、人間との会話は、最高のディープラーニングチャットボットを作成するための優先的な方法 です。データが多ければ多いほど、機械学習の効果は高まります。
ディープラーニングチャットボットとは何かがわかったところで、最初から構築する方法を理解してみましょう。
続きを読む:「ベトナムにオフショア開発センターを建設する方法(A-Z)」
ディープラーニングチャットボットの構築
1.データを準備する
機械学習関連のプロセスの最初のステップは、データの準備です。チャットボットをトレーニングするには、顧客とサポートスタッフの間に何千相互作用が必要です。
ディープラーニングチャットボット用の十分なデータポイントが存在するように、データは可能な限り詳細かつ多様である必要があります。この特定のプロセスは、オントロジーの作成と呼ばれます。この段階での唯一の目標は、できるだけ多くのインタラクティブを収集することです。
2.データの変形
これの観測は、クラシファイアに追加されるメッセージ応答ペアと呼ばれます。このステップの目標は、会話の応答として1人のスピーカーを置くことです。すべての着信ダイアログは、応答の予測に役立つテキストインジケータとして使用されます。メッセージと応答のペアを作成するときに、次のような制限を設定する必要がある場合があります。
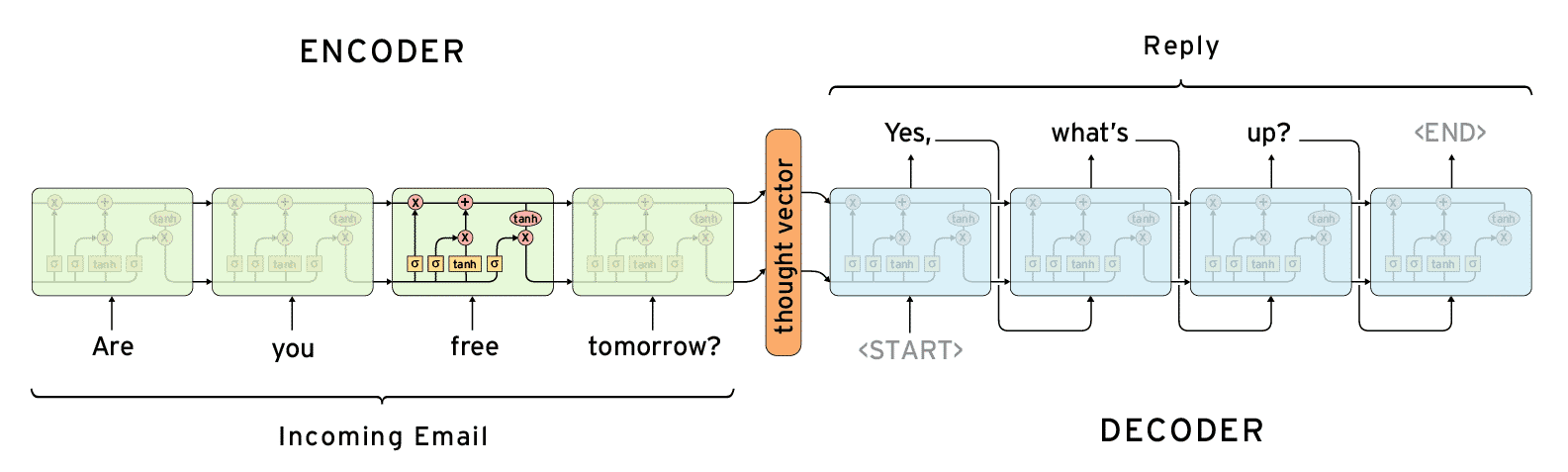
3.前処理
4.チャットボットのタイプを選択します
- ジェネレーティブ – ジェネレーティブモデルでは、チャットボットは事前定義されたリポジトリを一切使用しません。これは、ディープラーニングを使用してクエリに応答する高度な形式のチャットボットです。
- 検索ベース –このフォームでは、チャットボットはクエリの解決に使用する応答のリポジトリを持っています。質問に基づいて適切な応答を選択する必要があり、チャットボットはこれに準拠します。
検索モデルは、データの検索に完全に基づいているため、ほとんどミスを犯しません。ただし、これには別の制限があり、厳格すぎるように見えたり、応答が「人間的」に見えない場合があります。
一方、ディープラーニングチャットボットは、そのスタイルを顧客からの質問や要求に簡単に適合させることができます。ただし、このタイプのチャットボットでさえ、全然ミスをしない、人との活用を真似ることはできません。
チャットボットの包括モデルも、この分野の知識がかなり限られているため、完璧にするのが難しいです。実際、ディープラーニングチャットボットはまだチューリングテストに合格できていません 。
クエリが単純な場合、検索ベースのチャットボットは非常に役立ちますが、複雑なクエリにもチャットボットが必要です。これは、チャットボットが以前のメッセージでの発言も追跡する必要がある場合に特に当てはまります。検索ベースを元にづいてチャットボットは、簡単で安い質問を回答できます。
5.単語ベクトルを生成する
6.Seq2Seqモデルを作成する
Seq2Seqモデルを作成するため、TensorFlowを使用できます。このことを実施するため、次のようなPythonスクリプトを使用する必要があり ます。
すべてのことがする必要があるのは、コードに従い、ディープラーニングチャットボット用のPythonスクリプトを開発することです。このモデルの最も重要な部分はTensorFlowにembedding_rnn_seq2seq()です。
続きを読む:「ベトナムの高品質のオフショアITスタッフィング会社」
7.プロセスを追跡する
作成した後、 Seq2Seqモデル、トレーニングプロセスを追跡する必要があります。これは、ディープラーニングチャットボットがどのようにトレーニングされているかを確認できるという意味で楽しい部分です。
入力文字列を介してループのさまざまなポイントでチャットボットをテストする必要があります。非パッドおよび非EOSトークンが出力に返されます。
チャットボットはパディングとEOSトークンのみを出力するため、最初はほとんどの応答は空白になります。一般的に、チャットボットは、LOLなどの頻繁に使用される小さな出力文字列で応答を開始します。
徐々に、チャットボットは応答の開発を開始し、より長く、より完全な文章を出ます。時間の経過とともに、回答の構造と文法が改善されることがわかります。
8.アプリケーションに追加する
今あなたの Seq2Seqモデルは準備ができてテストされているので、人々が操作できる場所でモデルを起動する必要があります。説明のために、これはチャットボットを追加する最も簡単な方法の1つであるため、フェイスブックメッセージに限定します。
まず、Herokuサーバーをセットアップする必要があります。これは、Heroku toolbeltをダウンロードすることで実行できます 。次に、Nodeをインストールし、新しいフォルダーを作成して、新しいNodeプロジェクトを開始する必要があり ます。追加のノード依存関係をすべてインストールすることも必要です。これは次の方法で実行できます。
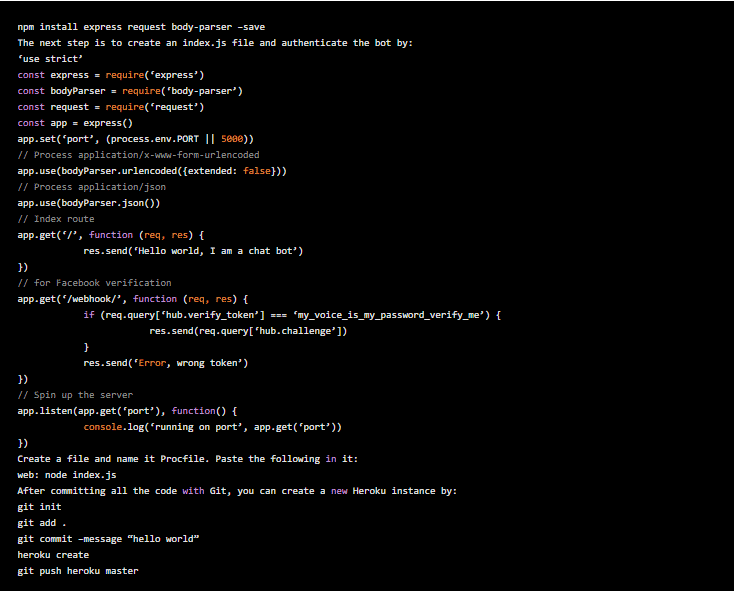
9. TensorFlowモデルをデプロイする
フェイスブックチャットボットの準備が整ったので、すべてを組み合わせてTensorFlowモデルをデプロイする必要があります。TensorFlowとノードの間に適切なインターフェースがあまりないため、モデルをデプロイするにはFlaskサーバーを使用する必要があります。
ディープラーニングチャットボットのExpressアプリはフラスコサーバーと対話します。
10.ディープラーニングチャットボットをテストする
11.改善方法
 チャットボットがより多くの会話からよりよく学習できるように、データセットをさらに追加します
チャットボットがより多くの会話からよりよく学習できるように、データセットをさらに追加します
最終的な考え
Innotech Japanのリソース
Innotech Japan は、ベトナムでの高品質サービスに焦点を当てたソフトウェアアウトソーシング企業です。 Innotech Japanでは、創造、革新、開発、高度なソリューションに取り組んでいます。 お客様からのすべての要件と期待に応える幅広いソフトウェアサービスを提供しています。 私たちは、世界中の専門的なソリューションとビジネスサービスを通じて、これらの高度なテクノロジーをお客様の価値に変えます。
ソフトウェアアウトソーシング開発に関する質問については、Innotech Japanの専門家にお問い合わせください。




