Introduction: The New Frontier of Australian Enterprise AI
In Australia’s rapidly maturing tech ecosystem, from the fintech hubs of Sydney to the mining giants in Perth, the novelty of “chatting” with AI has worn off. Organisations are now asking: How do we make this AI actually work for our specific business? The answer lies in creating a custom LLM.
While a pre-trained LLM like GPT-4 or Llama 3 offers a wide-ranging set of general capabilities, it often falters when faced with the specific knowledge of a niche industry. For an organisation to truly innovate, it must move beyond generic models and invest in custom LLM development to build systems that understand its proprietary data, local regulations, and unique brand voice. If you are looking to accelerate this transition, exploring a dedicated LLM Customizer is the most efficient path to tailoring these powerful tools to your operational needs.
What is a Custom LLM Model?
A custom LLM model is a large language model that has been specifically adapted to perform specific tasks or to operate within a private knowledge base. This adaptation bridges the gap between general artificial intelligence and specialised business utility.
Pre-training vs. Customisation
Most foundational AI models undergo pre-training on massive, public datasets to learn the fundamentals of natural language. However, to build a custom solution, developers take these pre-trained foundations and apply further training on domain-specific data. This ensures the model’s generated response is not just grammatically correct but factually accurate within the context of your business.
Why Australian Businesses Should Build Custom LLM Solutions
The drive to build custom LLM systems in Australia is fuelled by three primary factors: data security, accuracy, and competitive differentiation.
Enhanced Data Security and Sovereignty
Under the Australian Privacy Act, protecting sensitive information is paramount. Generic AI models often process data on international servers, which can be a deal-breaker for legal or medical firms. A custom model allows you to keep training data within your own controlled environment, significantly reducing the risk of data breaches or IP exposure.
Hallucination Reduction and Accuracy
Generic models often “hallucinate”—generating confident but false information. By creating a custom LLM grounded in your own facts, you ensure the AI remains a reliable tool for decision-making rather than a liability. For deeper insights into how these models are structured, professional resources like Towards Data Science offer excellent theoretical breakdowns.
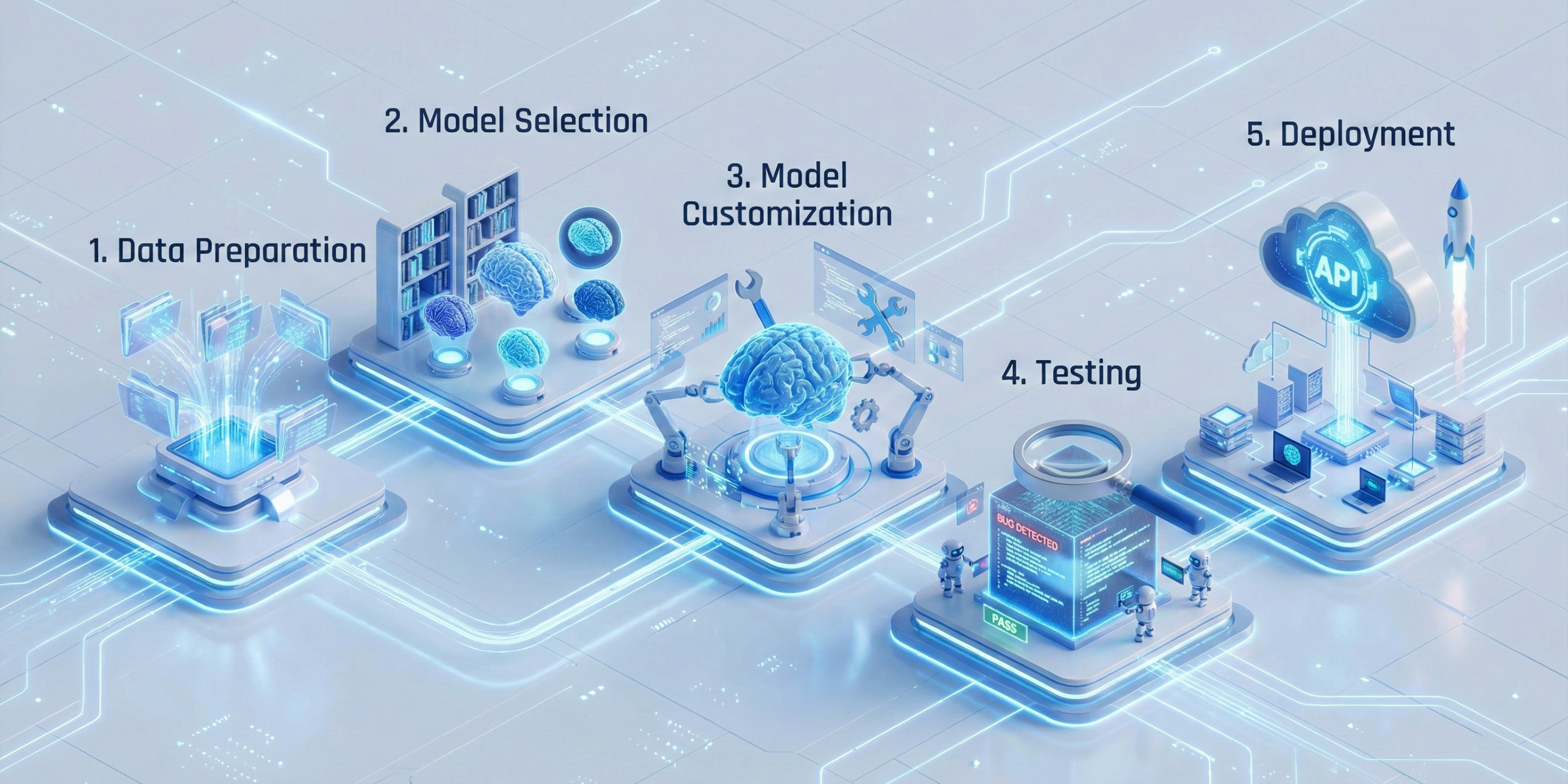
The Custom LLM Training Workflow: A Step-by-Step Guide
Successful custom LLM training follows a rigorous, iterative process to transform a foundation model into a specialised asset.
Step 1: Data Preparation and Cleaning
The quality of your AI model is directly tied to the quality of its data.
- Collection: Gather internal documents, manuals, and datasets.
- Cleaning: Remove duplicates, typos, and non-textual noise.
- Anonymisation: Scrub PII (Personally Identifiable Information) to ensure compliance with privacy laws.
- Tokenization: Convert the text into numerical formats that the model can process.
Step 2: Model Selection
Not all large language model architectures are the same.
- Large Models: 70B+ parameters offer high performance but require significant compute power.
- Smaller Models: Smaller models (7B–13B parameters) are faster, cheaper, and often sufficient for specific tasks.
Step 3: Customisation Techniques
This is the core of custom LLM development. You generally choose between two primary paths:
- Retrieval-Augmented Generation (RAG): Connects the model to a searchable database of your specific knowledge.
- Fine Tuning: Updates the model’s internal weights to learn new styles or deeper patterns.
Step 4: Iteration and Hyperparameter Tuning
Training involves adjusting settings like the learning rate and batch size. If the learning rate is too high, the model becomes unstable; if too low, training will be prohibitively slow. For developers looking to experiment with these parameters, GitHub remains the premier platform for accessing open-source fine-tuning scripts.
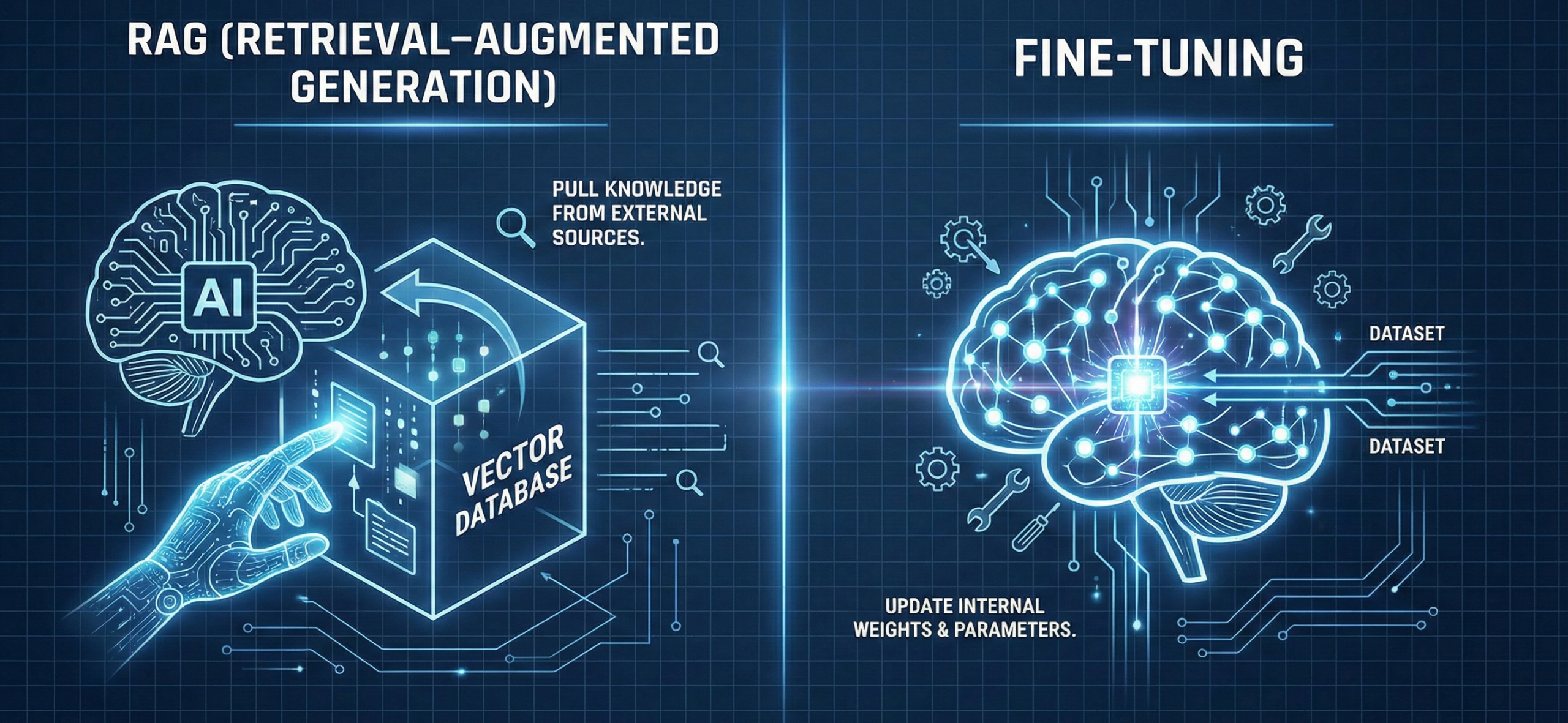
Deep Dive: Fine-Tuning vs. RAG
Understanding the difference between these hai techniques is essential for any organisation looking to build a custom AI solution.
Fine-Tuning: Teaching the Model New Skills
Fine-tuning involves feeding specialised datasets to the model to modify its internal parameters.
- Instruction Tuning: Trains the model to follow specific commands more effectively.
- PEFT (Parameter-Efficient Fine-Tuning): A method that updates only a small subset of parameters, saving time and cost.
- LoRA (Low-Rank Adaptation): Adds a modular “supplement” to the model, allowing it to adapt to new tasks without full retraining.
RAG: Giving the Model a Reference Library
RAG provides the model with “open-book” access to your data.
- Embeddings: Your data is converted into vectors in a searchable space.
- Retrieval: When a question is asked, the system finds the most relevant “chunks” of data.
- Accuracy: Because the model cites actual documents, RAG is the best way to reduce hallucinations for knowledge-intensive tasks.
For businesses that require a blend of both high-speed retrieval and deep stylistic learning, our LLM Customizer provides a unified interface to manage both RAG and fine-tuning workflows seamlessly.
Technical Infrastructure: Multiple GPUs and Data Flow
High-level custom LLM development requires serious hardware and careful resource management.
- Compute Power: Training often requires multiple GPUs to handle the parallel processing of massive datasets.
- Memory Management: Techniques like gradient checkpointing are used to reduce memory usage during the LLM training loop.
- Latency: Using smaller models or RAG can help reduce the time it takes for a model to generate a response, which is critical for user experience.

Case Studies: Australian Industry Impact
Implementing a custom model has already begun transforming various sectors across Australia.
Finance: Regulatory Compliance
A major Australian bank used custom LLM training to process decades of ASIC regulatory updates. By creating a custom LLM, they reduced the time compliance officers spent on research by 60%, ensuring all internal policies were up-to-date with the latest local laws.
Mining: Technical Manual Support
In the Pilbara region, engineers use a RAG-based custom LLM to query thousands of pages of technical equipment manuals. The AI provides an instant generated response to troubleshooting queries, drastically reducing downtime on remote sites.
HR: Smart Recruitment with Kingwork
Our partner platform, Kingwork.vn, integrates custom LLM model technology to automate the initial screening of resumes against specific Australian industry standards, ensuring that only the most qualified candidates are shortlisted for review.
Evaluation and JSON Enforcement
Before a model can be considered “production-ready,” it must undergo rigorous evaluation.
- Benchmarks: Tools like MMLU and HumanEval measure the model’s core intelligence and coding ability.
- Reliability: Using libraries like DeepEval helps ensure the model outputs valid JSON, which is essential for integrating the AI into existing software stacks without causing errors.
Conclusion: Starting Your Custom LLM Journey
Creating a custom LLM is a journey of continuous optimisation. For Australian enterprises, the benefits of data security, industry-specific accuracy, and improved efficiency make building custom LLM initiatives one of the most valuable investments in the modern era.
By following a step-by-step approach—from data curation to final evaluation—Innotech Vietnam helps businesses navigate the complexities of AI to deliver truly bespoke, powerful solutions.
Ready to transform your data into a competitive edge? Visit our LLM Customizer page to see how we can help you build and deploy your own private AI model today.




